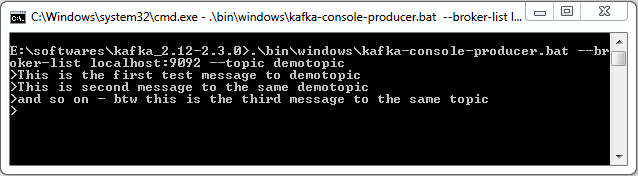
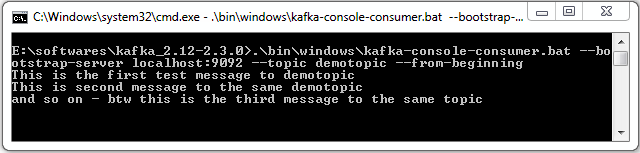
We will go through Apache Kafka Configuration settings which you need to do as part of setting up Apache Kafka.
Four Kafka Component Settings
- Broker Settings
- Producer Settings
- Consumer Settings
- Zookeeper Configuration with Kafka
Apache Kafka Configuration
1. Broker Settings
The Overall Performance of Kafka depends on the following Sub-settings.
1. Connection Settings
Zooker session timeout default value is 30000 ms(milliseconds).
zookeeper.session.timeout.msWithin this time the server sends Zookeeper heartbeat signals, if it fails to do so the server is considered to be dead.
Do not set this value too low, otherwise it will falsely consider a server dead, also do not set this value too high, otherwise zookeeper will take too long to determine a truly dead server.
2. Topic Settings
For each topic, Kafka maintains a structured commit log with one or more partitions. In general, the more the partitions in a Kafka cluster, more parallel consumers can be added, resulting in higher throughput.
Important Topic Properties
auto.create.topics.enableWith this property set to true nonexistent topics get created automatically with a default replication factor
default.replication.factorFor high availability production systems, you should set this value to at least 3.
num.partitionsFor automatically created topics it’s default value is 1. You can change based on requirements.
delete.topic.enableThis allows users to delete a topic from Kafka using the admin tool, if this property is turned off then Deleting a topic through the admin tool will have no effect.
By default this feature is turned off (set to false).
3. Log Settings
log.roll.hoursThe maximum time, in hours, before a new log segment is rolled out. The default value is 168 hours (seven days).
This setting controls the period of time after which Kafka will force the log to roll, even if the segment file is not full. This ensures that the retention process is able to delete or compact old data.
log.retention.hoursThe number of hours to keep a log file before deleting it. The default value is 168 hours (seven days).
log.dirsA comma-separated list of directories in which log data is kept. If you have multiple disks, list all directories under each disk.
log.retention.bytesThe amount of data to retain in the log for each topic partition. By default, log size is unlimited.
If log.retention.hours and log.retention.bytes are both set, Kafka deletes a segment when either limit is exceeded.
log.segment.bytesThe log for a topic partition is stored as a directory of segment files. This setting controls the maximum size of a segment file before a new segment is rolled over in the log. The default is 1 GB.
Log Flush Management
log.flush.interval.messagesSpecifies the number of messages to accumulate on a log partition before Kafka forces a flush of data to disk.
log.flush.scheduler.interval.ms Specifies the amount of time (in milliseconds) after which Kafka checks to see if a log needs to be flushed to disk.
log.segment.bytesSpecifies the size of the log file. Kafka flushes the log file to disk whenever a log file reaches its maximum size.
log.roll.hours Specifies the maximum length of time before a new log segment is rolled out (in hours); this value is secondary to log.roll.ms. Kafka flushes the log file to disk whenever a log file reaches this time limit.
4. Compacting Settings
log.cleaner.dedupe.buffer.sizeSpecifies total memory used for log de-duplication across all cleaner threads.
By default, 128 MB of buffer is allocated.
log.cleaner.io.buffer.sizeSpecifies the total memory used for log cleaner I/O buffers across all cleaner threads. By default, 512 KB of buffer is allocated.
5. General Broker Settings
auto.leader.rebalance.enableEnables automatic leader balancing, default is enabled.
unclean.leader.election.enableThis property allows you to specify a preference of availability or durability. This is an important setting: If availability is more important than avoiding data loss, ensure that this property is set to true. If preventing data loss is more important than availability, set this property to false.
This property is set to true by default, which favors availability.
controlled.shutdown.enableEnables controlled shutdown of the server. The default is enabled.
min.insync.replicasWhen a producer sets acks to “all”, min.insync.replicas specifies the minimum number of replicas that must acknowledge a write for the write to be considered successful. If this minimum cannot be met, then the producer will raise an exception.
You should set min.insync.replicas to 2 for replication factor equal to 3.
message.max.bytesSpecifies the maximum size of message that the server can receive.
broker.rackThe rack awareness feature distributes replicas of a partition across different racks.
2. Producer Settings
The lifecycle of a request from producer to broker involves several configuration settings:
The producer polls for a batch of messages from the batch queue, one batch per partition. A batch is ready when one of the following is true:a. batch.size is reached. Note: Larger batches typically have better compression ratios and higher throughput, but they have higher latency.
a. batch.size is reached. Note: Larger batches typically have better compression ratios and higher throughput, but they have higher latency.
b. linger.ms (time-based batching threshold) is reached. Note: There is no simple guideline for setting linger.ms values; you should test settings on specific use cases. For small events (100 bytes or less), this setting does not appear to have much impact.
c. Another batch to the same broker is ready.
d. The producer calls flush() or close().
Some additional settings
max.in.flight.requests.per.connection (pipelining)compression.typeIt accepts standard compression codecs (‘gzip’, ‘snappy’, ‘lz4’), as well as ‘uncompressed’ (the default, equivalent to no compression).
acksThe acks setting specifies acknowledgments that the producer requires the leader to receive before considering a request complete. This setting defines the durability level for the producer.
if Acks = 0; it means High Throughput , Low latency
if Acks = 1; it means medium Throughput , medium latency
if Acks = -1; it means low Throughput , High latency
flush() : which makes all buffered records immediately available to send (even if linger.ms is greater than 0).
3. Consumer Settings
One basic guideline for consumer performance is to keep the number of consumer threads equal to the partition count.
4. Zookeeper Configuration with Kafka
Some recommendations :
- Do not run ZooKeeper on a server where Kafka is running.
- Make sure you allocate sufficient JVM memory. A good starting point is 4GB.
- To monitor the ZooKeeper instance, use JMX metrics.
- When using ZooKeeper with Kafka you should dedicate ZooKeeper to Kafka, and not use ZooKeeper for any other components.
Summary
In this article we saw some configuration settings of Kafka components for it to run with high performance, we saw some recommended settings and what each setting means.
I Hope you liked the article !