The Hashset class implements the Set interface. The underlying data structure for hashset is the hashtable The insertion order is not maintained in Set, Objects are inserted based on hashcodes. It allows to store null elements.
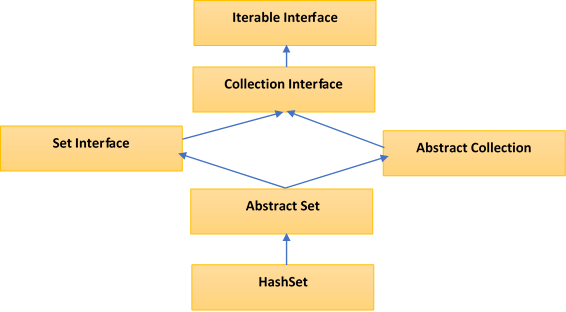
Hierarchy of HashSet class
public class HashSet<E> extends AbstractSet<E>
implements Set<E>, Cloneable, Serializable
{ //implementation }
The HashSet class extends AbstractSet class which implements Set interface. The Set interface inherits Collection and Iterable interfaces in hierarchical order.
HashSet Constructors
- HashSet hs = new HashSet();
Default initial capacity is 16 and default load factor is 0.75. - HashSet hs = new HashSet(int initialCapacity);
initializes a HashSet with a specified capacity. - HashSet hs = new HashSet(int initialCapacity, float loadFactor);
initializes a HashSet with a specified capacity and load factor (0.75) - HashSet hs = new HashSet(Collection C);
It is used to initialize HashSet with the elements of Collection(Eg: an arraylist)
Initial Capacity
Initial Capacity means the number of buckets in the HashSet(internally backing HashMap) when it is created and ofcourse the number of buckets will increase automatically if the current size gets full.
By Default : the initial capacity is 16, we can override this by passing the capacity in one of its Constructors like this : HashSet(int initialCapacity).
Load Factor
The load factor is a measure of how full the HashSet is allowed to get before its capacity is automatically increased and the Default load factor is 0.75.
There is a threshold before the backing hashtable gets rehashed. So when the number of entries in the hash table exceeds the threshold (which is the product of the load factor and the current capacity), then the hash table is rehashed (which means, internal data structures are rebuilt) so that the hash table has approximately twice the number of buckets.
By Default : In the HashSet, the internal capacity is 16 and load factor is 0.75. The number of buckets will automatically get increased when the table has 12 elements(16 X 0.75) in it.
Internal working of a HashSet
All the classes of Set interface internally backed up by Map. HashSet uses HashMap for storing its object internally. You must be wondering that to enter a value in HashMap we need a key-value pair, but in HashSet we are passing only one value.
Storage in HashMap
Actually the value we insert in HashSet acts as key to the map Object and for its value java uses a constant variable. So in key-value pair all the keys will have same value
If we look at add() method of HashSet class:
public boolean add(E e)
{
return map.put(e, PRESENT) == null;
}
/* Where PRESENT is a Dummy value to associate with an Object in Map
private static final Object PRESENT = new Object(); */
Methods in HashSet Class
| S.No | Method | Description |
|---|---|---|
| 1 | boolean add(E e) | This method Adds the specified element to the set if it is not already present. Important : This method internally uses equals() method, so it the element is duplicate it is not added to the set. |
| 2 | boolean contains(Object o) | Returns true if this set contains the specified element else returns false |
| 3 | boolean isEmpty() | Returns true if this set contains no elements. |
| 4 | boolean remove(Object o) | Removes the specified element from this set if it is present. |
| 5 | void clear() | Removes all of the elements from this set. |
| 6 | Object clone() | Returns a shallow copy of this HashSet instance: the elements themselves are not cloned. |
| 7 | Iterator iterator() | Returns an iterator over the elements in this set. |
| 8 | int size() | Returns the number of elements in this set (its cardinality). |
| 9 | Spliterator spliterator() | Creates a late-binding and fail-fast Spliterator over the elements in this set. |
Coding Examples
1. Add, remove and iterate over HashSet
//1.Create HashSet
HashSet<String> hs = new HashSet<>();
//2.Add elements to HashSet
hs.add("Apple");
hs.add("Ball");
hs.add("Cat");
hs.add("Dog");
hs.add("Elephant");
System.out.println("HashSet : "+hs);
//3.Check if element exists
boolean found = hs.contains("Apple"); //true
System.out.println("Found : "+found);
//4.Remove an element
hs.remove("Dog");
//5.Iterate over values
Iterator<String> itr = hs.iterator();
System.out.println("HashSet After removal of Dog -")
while(itr.hasNext())
{
String value = itr.next();
System.out.println("Value: " + value);
}
Output
HashSet : [Apple, Ball, Cat, Dog, Elephant]
Found : true
HashSet After removal of Dog -
Value: Apple
Value: Ball
Value: Cat
Value: Elephant
2. Create HashSet from another Collection
public static void main(String args[]){
ArrayList<String> list=new ArrayList<String>();
list.add("Apple");
list.add("Ball");
HashSet<String> hs=new HashSet(list);
hs.add("Cat");
Iterator<String> i=hs.iterator();
while(i.hasNext())
{
System.out.println(i.next());
}
}
Output
Apple
Ball
Cat
3. Convert HashSet to ArrayList using java 8 Stream Apis
HashSet<String> hs = new HashSet<>();
hs.add("Apple");
hs.add("Ball");
hs.add("Cat");
List<String> arrayList = hs.stream().collect(Collectors.toList());
System.out.println(arrayList);
Output
[Apple, Ball, Cat]
When to use HashSet ?
Yes developers may also use ArrayList for storing elements, But in Scenarios where you want to have distinct elements with no duplicates, use of HashSet will be very useful.
Difference between HashSet and TreeSet
| S.No | HashSet | TreeSet |
|---|---|---|
| 1 | For operations like search, insert and delete. It takes constant time for these operations on average. HashSet is faster than TreeSet. HashSet is Implemented using a hash table | TreeSet takes O(Log n) for search, insert and delete which is higher than HashSet. But TreeSet keeps sorted data. TreeSet is implemented using a Self Balancing Binary Search Tree (Red-Black Tree). TreeSet is backed by TreeMap in Java. |
| 2 | Elements in HashSet are not ordered. | maintains objects in Sorted order defined by either Comparable or Comparator method in Java. TreeSet elements are sorted in ascending order by default. |
| 3 | HashSet allows null object | TreeSet doesn’t allow null Object and throw NullPointerException, Why, because TreeSet uses compareTo() method to compare keys and compareTo() will throw java.lang.NullPointerException. |
| 4 | HashSet uses equals() method to compare two object in Set and for detecting duplicates. | TreeSet uses compareTo() method for same purpose. If equals() and compareTo() are not consistent, i.e. for two equal object equals should return true while compareTo() should return zero, than it will break contract of Set interface and will allow duplicates in Set implementations like TreeSet |